Bank of America POC
Nikola Tulechki
2018-12-14
1 Context and scope
1.1 Project
- Client
- Bank Of America (BOA) - Huge private US bank
- Cyber Threat Intelligence (CTI) Department
- Project @ Onto
- 6 month POC
- $50K
1.2 Context - Open source intelligence
“Open Source Intelligence (OSINT) is data collected from publicly available sources to be used in an intelligence context.” Lately not only collection but active sharing of info and data
- Commercial data providors - MITRE corp, Symantec, Kaspersky
- Dedicated data model (STIX)
- MISP Open Source Threat Intelligence Platform & Open Standards For Threat Information Sharing (EU initiative)
1.3 Task - Cyber Threat report screening
- A constant stream of textual documents describing new cyber threats
- High priority on being up to date
- High load on SME for document screening
1.4 Scope recap
Integrate public data sources in a client ontology and build a Knowledge Graph
Automatically extract instance data from raw text and further populate the Knowledge Graph
Main difficulty: Entities manifest at different levels:
- Simple Named Entities - (Software, Groups etc) - trivial to annotate automatically using a gazeteer
- Complex entities such as techniques and tactics are more complicated
1.5 Project outline
- Data modelling and Integration
- Design NLP pipeline for processing threat reports
- Annotate complex entities in text for a training corpus
- Bundle in a UI and show value
2 Data Modelling and Integration
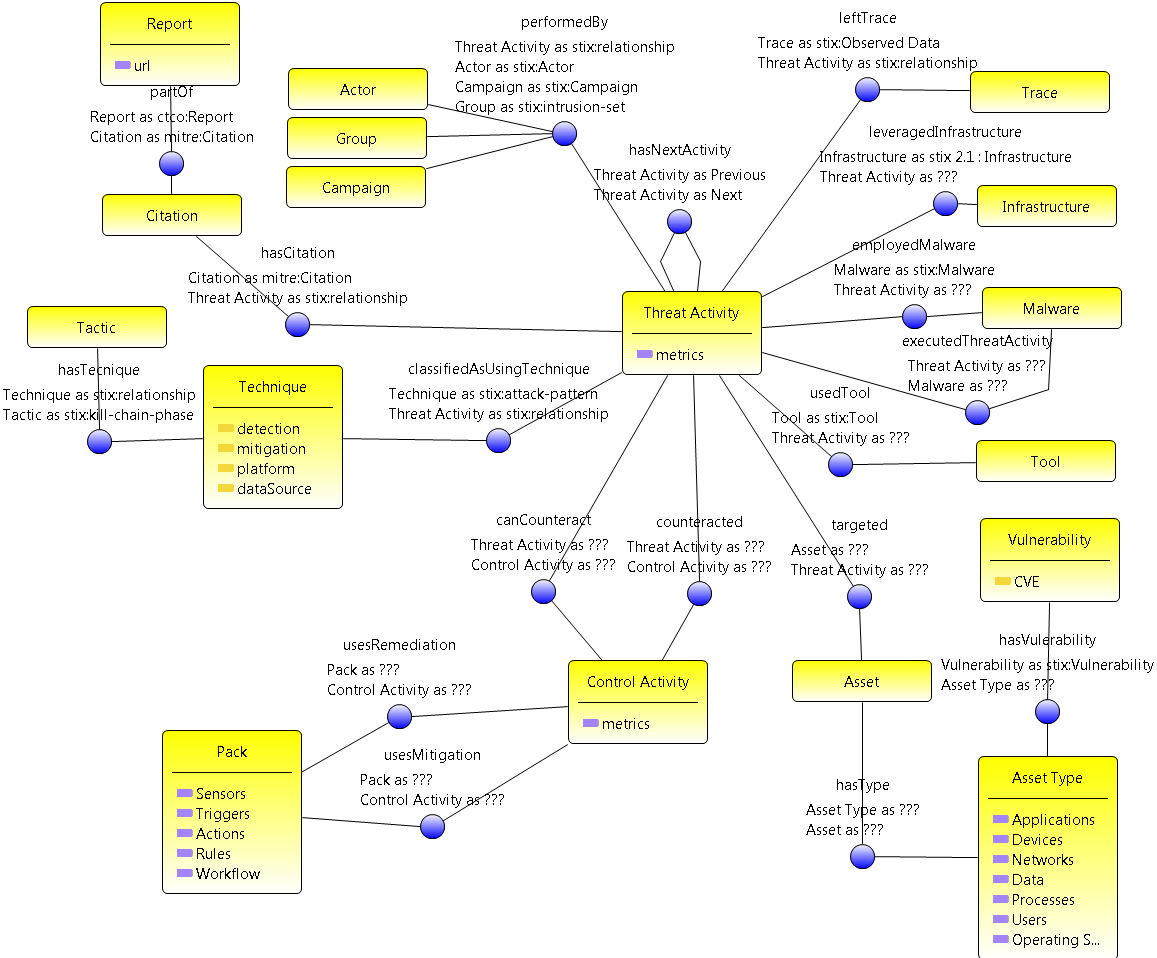
2.1 The problem
- Client’s ontology - his first ontology
- Source data in STIX model (json format)
- Ingest data and build a KG
{kind=link}
2.2 The solution
- Analysed and understood the data
- Mapping from STIX to client’s model
- Directly ingested of STIX data using json.ld
- Mapping and conversion using SPARQL queres
2.3 Lessons learned
- A lot of effort around validating and tweaking the client’s ontology
- New data came in after the modelling, integration phase was done
- 3 final redundant repos and some last-minute tweaks and kludges.
- Should have worked to stop the datawork and agree on the sources early on
3 NLP pipeline
3.1 The problem
- Annotate documents with the relevant business types
- Simple gazeteer based annotations from the KG
- Complex sentence level entities need to somehow be captured
3.2 The solution
- Gazeteer from KG - based on the DSP Pipeline with most of the stuff removed
- Complex entities not captured by a gazeteer
- Machine learning approach (sentence classification)
- No training data -> have them annotate a bunch of docs
3.3 Lessons learned
- Too ambitious for a POC
- Possibility of rule-based / string matching approach from the wiki/KG
- Bootstrap the manual annotation task
- Problems with lately ingested data
- No startegy for disambiguation (Malware called “first”), clean up gazetteer by hand…
4 Manual annotation task
4.1 The problem
- Build training data for entities of type “Tactic” and “Technique”
- Rougly sentence-sized.
- Examples (from manual annotations):
- “If a malicious document is opened” : User Execution
- “keylogging capabilities” : Input Capture
- “Encapsulated PostScript (EPS) object is embedded within the document in order to execute” : Scripting
4.2 The solution
- Set up a manual annotation task using Ontotext/Data Stork Curation Tool
- 2 Annotators SME - 1200 docs target
- Collaboratively produce annotation guidelines
- 2 days training sessions
- Curation tool demo
4.3 Lessons learned
- Manual annotation is hard and costly
- 60 docs of 1200 annotated docs
- Gross underestimation of the effort required
- Lack of real commitment from the client
- No clear strategy for managing anonymous annotations and closing the loop to the knowledge graph
- Beta (alpha?) testing a new tool during a commercial project can be messy and stressful
- Bugs, missing features
- Unclear workflow
{kind=link}
5 UI and value delivery
5.1 The problem
- Visually showcase the work done in the project
- Show annotated documents
- Demo of the Knowledge Graph
5.2 The solution
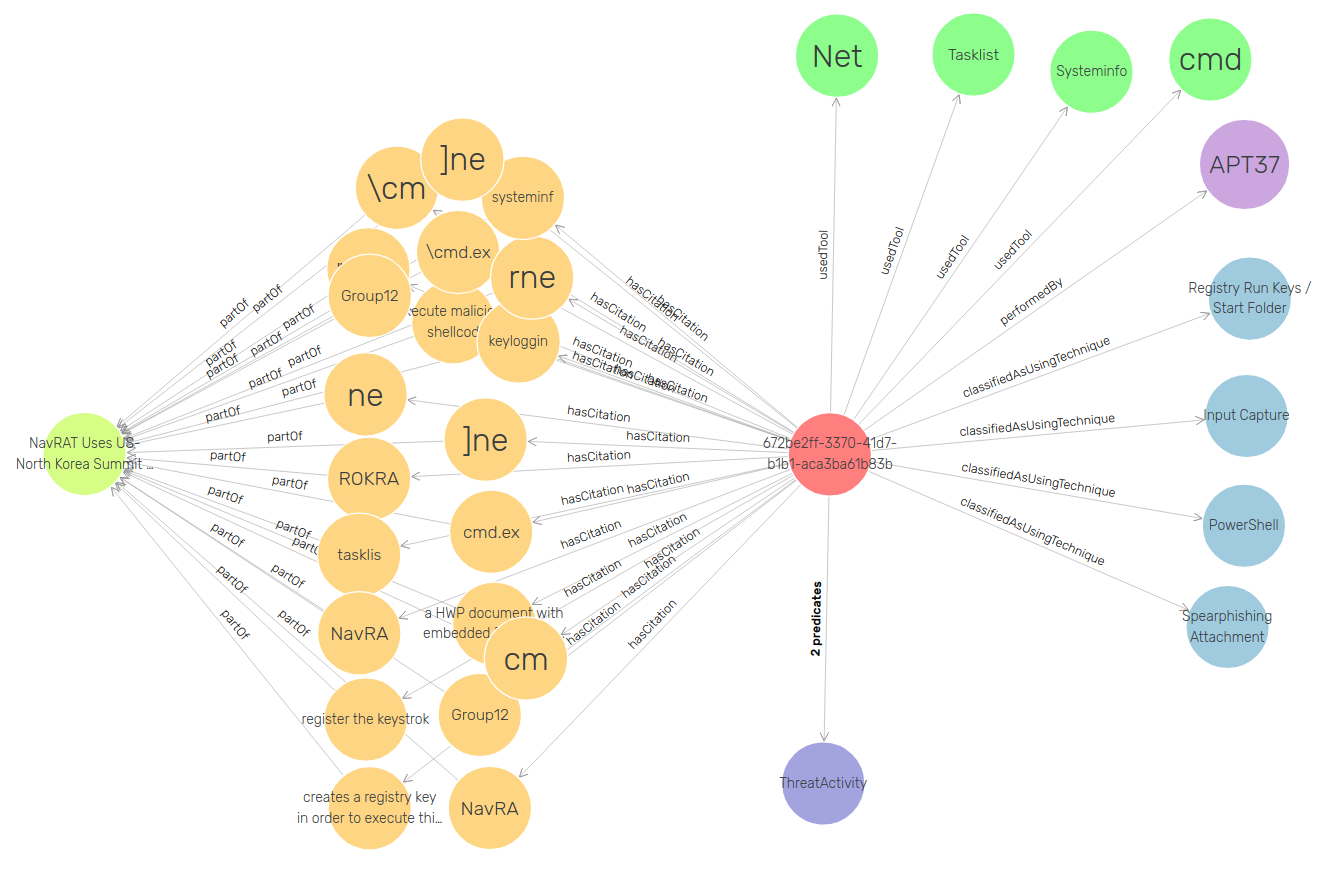
- Adapt Ontotext NOW UI to work with Threat Reports
- Use GDB Visual Graph to showcase the Knowledge Graph
{kind=link}
5.3 Lessons learned
- Ontotext NOW was too tightly associated with the publishing domain
- Lead ultimately to a total refactoring (still ongoing)
- Easily deploy the UI in similar projects in the future.
- Very good feedback from GDB workbench visual graph
- Some usability issues forwarded to GDB team
- Need to discuss the possibility to somehow get the visualisations out of Workbench
6 Thank You

@ Onto Lunch and Share